
Pretend your PC Archives

pretend your PC Archives
Malware
Worm
A computer worm is a type of Trojan that is capable of propagating or replicating itself from one system to another. It can do this in a number of ways. Unlike viruses, worms don’t need a host file to latch onto. After arriving and executing on a target system, it can do a number of malicious tasks, such as dropping other malware, copying itself onto devices physically attached to the affected system, deleting files, and consuming bandwidth.
CONTINUE READING
Malware
Trojans
Trojan is a malware that uses simple social engineering tricks in order to tempt users into running it. It may pretend to be another, legitimate software (spoofing products by using the same icons and names). It may also come bundled with a cracked application or even within a freeware.
Once it is installed on the computer, it performs malicious actions such as backdooring a computer, spying on its user, and doing various types of damage.
Trojans are not likely to spread automatically. They usually stay at the infected host only.
CONTINUE READING
Malware
Trojan dropper
Downloaders and droppers are helper programs for various types of malware such as Trojans and rootkits. Usually they are implemented as scripts (VB, batch) or small applications.
They don’t carry any malicious activities by themselves, but just open a way for attack by downloading/decompressing and installing the core malicious modules. To avoid detection, a dropper may also create noise around the malicious module by downloading/decompressing some harmless files.
Very often, they auto-delete themselves after the goal has been achieved.
CONTINUE READING
Malware
Rootkits
The term “rootkit” comes from “root kit,” a package giving the highest privileges in the system. It is used to describe software that allows for stealthy presence of unauthorized functionality in the system. Rootkits modify and intercept typical modules of the environment (OS, or even deeper, bootkits).
Rootkits are used when the attackers need to backdoor a system and preserve unnoticed access as long as possible. In addition, they may register system activity and alter typical behavior in any way desired by the attacker.
Depending on the layer of activity, rootkits can be divided into the following types:
Usermode (Ring 3): the most common and the easiest to implement, it uses relatively simple techniques, such as IAT and inline hooks, to alter behavior of called functions.
Kernelmode (Ring 0): the “real” rootkits start from this layer. They live in a kernel space, altering behavior of kernel-mode functions. A specific variant of kernelmode rootkit that attacks bootloader is called a bootkit.
Hypervisor (Ring -1): running on the lowest level, hypervisor, that is basically a firmware. The kernel of the system infected by this type of a rootkit is not aware that it is not interacting with a real hardware, but with the environment altered by a rootkit.
The rule states that a rootkit running in the lower layer cannot be detected by any rootkit software running in all of the above layers.
CONTINUE READING
Malware
Remote Access Trojan (RAT)
Remote Access Trojans are programs that provide the capability to allow covert surveillance or the ability to gain unauthorized access to a victim PC. Remote Access Trojans often mimic similar behaviors of keylogger applications by allowing the automated collection of keystrokes, usernames, passwords, screenshots, browser history, emails, chat lots, etc. Remote Access Trojans differ from keyloggers in that they provide the capability for an attacker to gain unauthorized remote access to the victim machine via specially configured communication protocols which are set up upon initial infection of the victim computer. This backdoor into the victim machine can allow an attacker unfettered access, including the ability to monitor user behavior, change computer settings, browse and copy files, utilize the bandwidth (Internet connection) for possible criminal activity, access connected systems, and more.
CONTINUE READING
Malware
Rogue scanners
Rogue scanners, also known as fake scanners, fake AV, or rogueware, are pieces of code injected into legitimate sites or housed in fake sites. Their social engineering tactic normally involve displaying fictitious security scan results, threat notices, and other deceptive tactics in an effort to manipulate users into purchasing fake security software or licenses in order to remove potential threats that have supposedly infected their systems. Their warnings were deliberately crafted to closely resemble interfaces of legitimate AV or anti-malware software, further increasing the likelihood that users who see them will fall for the ploy. These malware can target and affect PCs and Mac systems alike. In 2011, known names in the security industry have noted the dramatic decline of rogue scanners, both in detection of new variants and search engine results for their solutions.
Rogueware is one of two main classes of scareware. The other is ransomware. Rogue scanners are not as apparent as they used to be several years ago. It is believed that ransomware has completely replaced rogue scanners altogether.
CONTINUE READING
Malware
Point of Sale (POS)
Point-of-sale (POS) malware is software specifically created to steal customer data, particularly from electronic payment cards like debit and credit cards and from POS machines in retail stores. It does this by scraping the temporarily unencrypted card data from the POS’s memory (RAM), writing it to a text file, and then either sending it to an off-site server at a later date or retrieving it remotely. It is believed that criminals behind the proliferation of this type of malware are mainly after data they can sell, not for their own personal use. Although deemed as less sophisticated than your average PC banking Trojan, POS malware can still greatly affect not just card users but also merchants that unknowingly use affected terminals, as they may find themselves caught in a legal mess that could damage their reputation.
POS malware may come in three types: keyloggers, memory dumpers, and network sniffers.
CONTINUE READING
Malware
Info stealers
The term info stealer is self-explanatory. This type of malware resides in an infected computer and gathers data in order to send it to the attacker. Typical targets are credentials used in online banking services, social media sites, emails, or FTP accounts.
Info stealers may use many methods of data acquisition. The most common are:
- hooking browsers (and sometimes other applications) and stealing credentials that are typed by the user
- using web injection scripts that are adding extra fields to web forms and submitting information from them to a server owned by the attacker
- form grabbing (finding specific opened windows and stealing their content)
- keylogging
- stealing passwords saved in the system and cookies
Modern info stealers are usually parts of botnets. Sometimes the target of attack and related events are configured remotely by the command sent from the Command and Control server (C&C).
CONTINUE READING
Malware
DNS hijacker
DNS changers/hijackers are Trojans crafted to modify infected systems’ DNS settings without the users’ knowledge or consent. Once the systems are infected and their DNS settings modified, systems use foreign DNS servers set up by the threat actors. Infected systems that attempt to access specific sites are redirected to sites specified by threat actors.
CONTINUE READING
These free Wayback Machine hacks will make you a better online sleuth
You may already know about a website that lets you peek into the past. This week, we dig into tools on that site that make it easy to save what you find.
Hare: Hey, Ren, what are we talking about this week?
LaForme: Let’s talk about history. Most people are aware of the Internet Archive Wayback Machine. For those who aren’t aware of it, the Wayback Machine is a search service that can show you old versions of a website. This is great because, as we know, sometimes people try to change things on their websites — which are essentially their online personas — and pretend like it didn’t happen.
I’ve been using it for years and years, but this week I spoke to Gary Price, a researcher, librarian and founder of Infodocket.com, who clued me in on some Wayback Machine features I never knew about.
Hare: Oh excellent. Librarians are always full of good surprises.
LaForme: I wish newsrooms still kept a bunch of them around. That’s a huge loss for us.
Anyway, the first thing I learned about the Wayback Machine is that you can actually set it to capture a page manually. There’s a little search bar on the bottom right side of the Wayback Machine home page (notably, it’s not on the archive.org homepage) that lets you enter a URL and grab any page that’s currently online.
It also gives you the option to download a PDF of that page as it’s captured. That’s something you can already do from most browsers, but it’s a great two-step process of capturing a site that you think needs to be archived for some purpose.
Hare: I love shortcuts. How do you see journalists using this?
LaForme: As a journalist, I’m particularly interested in holding those in power accountable. So I’m going to suggest grabbing archives of government websites, websites for big corporations, large donors to politicians and lobbyists and the like, and other organizations with power.
But you can literally use it for anything. I mean, if you’re particularly proud of how your news organization’s front page is looking on a given day, grab an archive. People will see it when they go back to look at that URL in the Internet Archive.
Hare: We’ve talked before about other ways to monitor changes on websites, but I want to spend a little more time on the second function you mentioned: archiving your own work. I wrote about this a few years ago, told myself I needed to go save some stories from when I lived in St. Louis, and now a lot of them are gone. When your work appears on the internet, it’s really easy for it to just disappear.
I spoke to someone at RJI who’s working on this, and his advice was – make a PDF of your stories. This seems like a very easy way to set that up.
LaForme: Absolutely. My online writing only goes back a little over a decade, but I’d say that half of it has already been swallowed by the shifting sands of the internet. I’m missing a ton of articles from high school and college, maybe for the better.
My advice for that, since the Internet Archive focuses more on homepages, would be to use your browser to grab PDFs of your articles. On a Mac, you just hit the print button under “File” on any browser and use the PDF functionality within it. On a PC, I think it’s roughly similar, but it depends on the browser. It should take you just a few seconds for each article. I’d recommend keeping them in a folder that syncs to Google Drive or Dropbox just to make sure they’re safe.
Hare: That’s embarrassingly simple. What else did you learn about?
LaForme: Oh, this one makes it even easier. You know I love shortcuts and making workflows easier, so the second thing I learned is that there’s a bookmarklet that lets you archive a page without going to the Wayback Machine website. Since it’s a bookmarklet, it should work on all browsers. It’s a handy little tool.
Hare: Yes, the less steps the better. This is why I’m horrible at cooking. (Gonna keep telling myself that.) Have you seen any cool ways journalists have used WBM?
LaForme: I think it’s most useful as a research tool, which is how most journalists are using it. So, if you’re using it the way I described, you’re basically giving the future version of you a high five and making it easier to conduct research in the future. I think I’m going to start caching the websites of major digital tool makers just so I can have something to look back on.
Hare: Agreed, it’s a great way to peek into the past and see what the places and people we cover were like. Is there anything you’d change or add if you could?
LaForme: I do wish it went deeper on websites, but can you imagine the storage that would take? It would be ridiculous. Also, it doesn’t have the ability to archive sites with anti-crawling code.
One limitation I found the other day, when I accidentally deleted a friend’s entire front page layout, is that it doesn’t capture the CSS and images for every site. I had to use another site, called Cachedview, to grab all of that stuff to fix his site. Just another reminder that it’s important to employ a whole toolbox from time to time.
Hare: Want to see something cool?
LaForme: Obviously!
Hare:
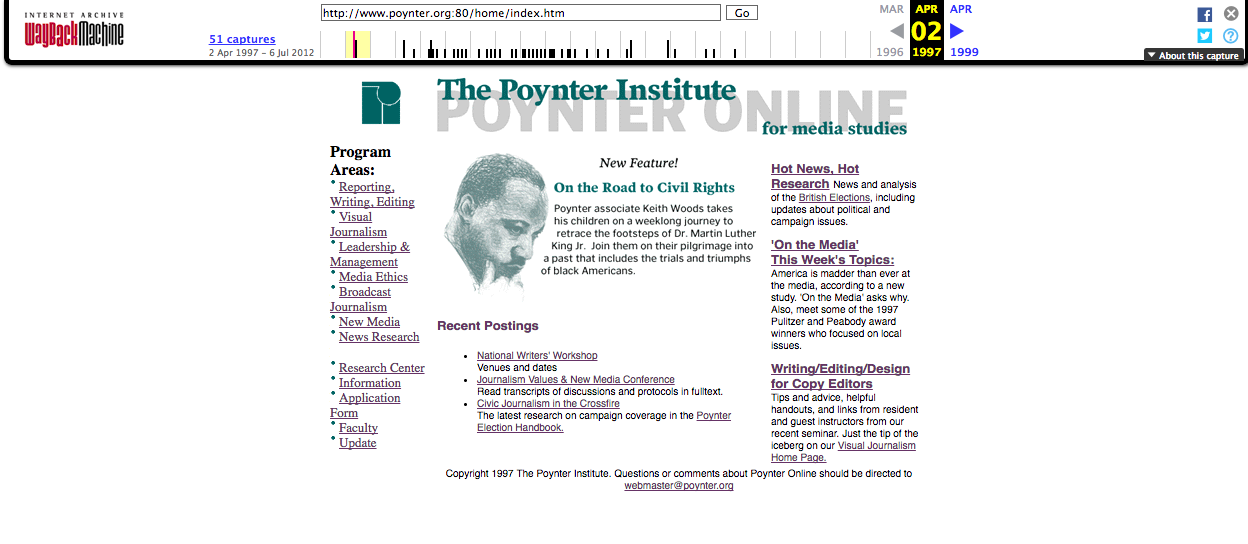
Poynter.org circa 1997.
“America is madder than ever at the media, according to a new study.”
Guess it’s been a rough two decades…
LaForme: Wow! Look at that page. It’s… something. I guess some things change and others don’t change that much at all.
Editor’s note: This is the latest in a series of articles that highlight digital tools for journalists. You can read the others here. Got a tool we should talk about? Let Renknow!
Learn more about journalism tools with Try This! — Tools for Journalism. Try This! is powered by Google News Lab. It is also supported by the American Press Institute and the John S. and James L. Knight Foundation.
PERSONAL COMPUTERS; Of Memories and Memory and Yet More Memory
PERSONAL COMPUTERS
August 24, 1993, Section C, Page 11Buy Reprints
BOB K., an electrician, was in the dark. He had received a used computer in barter for his services and called for advice. "It has 40 megabytes of memory," he said, revealing that he is one of many novice computer users who are understandably confused by the difference between system memory and storage memory.
Personal computers can have several types of memory, each of which performs a separate function. Random access memory (RAM), read-only memory (ROM), video RAM (VRAM) and storage memory are the most common memories a user will encounter these days.
Before discussing memory, let us pause for a byte. Computer memory is measured in units called bytes. It takes eight bits to make a byte. It takes about a thousand bytes to make a kilobyte, about a thousand kilobytes to make a megabyte, and about a thousand megabytes to make a gigabyte. The numbers are approximations because in the binary math of computers a kilobyte is actually 1,024 bytes. Unless one cares to count each byte, it is easier to round off the numbers.
In a sense Mr. K's computer does have 40 megabytes of memory, but it is a secondary and indirect type of memory, for data storage. When one refers to the memory of a personal computer, it is generally understood to mean random access memory, or RAM, also called system memory or main memory. This type of memory is more critical to the performance of the computer because the microprocessor draws on it directly.
An analogy close at hand is this newspaper, which consists of many pages of words and pictures. The newspaper stores all of this information as ink on paper, while a hard disk stores its data as microscopic bumps on a spinning magnetic platter.
Let us assume the "storage capacity" of this newspaper is 40 megabytes, the same as Mr. K's computer. Actually, the text alone is probably less than a megabyte, but let's pretend.
And while we are at it, let's pretend that you, the reader, are a computer. Your brain is the microprocessor. At the risk of stretching the analogy too far, how fast you read and process information is determined by the speed and power of your processor. Some of us have Intel 286's for brains, while others have 386's and 486's and Pentiums.
The information residing on the pages of the newspaper is memory in one sense, because it is information that can be retrieved and processed by our microprocessors. But only a small portion of the newspaper's information can be processed at any given time, and that is where RAM comes in.
Our own built-in microprocessors cannot absorb the 40 megabytes of this newspaper all at once. The outspread pages would not fit in our range of vision, let alone our capacity to consider several dozen articles at once. Our brains do not have enough RAM.
It is common, however, to look at one page of the newspaper at a time (1MB RAM, in our analogy, the same as Mr. K's computer). Many people hold the paper open to scan across two pages at a time (2MB RAM), while others fold a page in half (512KB RAM). The key is that all the information on that page is accessible almost instantly, just by moving one's eyes from one item to the next. All the articles on the page are essentially "in memory," even though the reader's focus may be on just one item.
If the article is too large to fit on one page, the microprocessor issues a seek instruction; the reader looks for the "continued on page X" address and turns to that page to continue reading, in effect taking one page out of RAM and putting another in its place.
The more RAM a system has, the more information and activities are available instantly, without having to go back and forth to storage memory. With lots of RAM, a reader would be able to take down notes about this article, use a calculator to multiply 1,024 by 1,024 to find the true number of bytes in a megabyte, check one's wristwatch, eat a bagel and drink a cup of coffee. With less RAM, each operation might have to be done one at a time. The computer may announce the dreaded "Not enough memory available" message.
The computer user almost never has to deal with ROM, or read only memory, which is programmed in the factory and safeguarded against meddling by the user. ROM contains the basic instructions needed to coordinate the various components of the computer, including microprocessor, disk drives, monitor, keyboard and so on. The instructions for moving one's arms and hands to turn the newspaper page and bring it in front of the eyes, for example, might be thought of as ROM.
Video RAM is increasingly important for people who work with Windows and visual images. It will be discussed in a future column.
A typical computer today comes with 4MB RAM and an 80MB hard disk, which is enough to do basic work with Microsoft Windows and Windows software. Windows has become the de facto standard for software, so it is a good idea to buy a computer with enough RAM and hard disk space to accommodate it.
A computer with 2MB or less of RAM and 20MB or less of hard disk space is adequate for simple DOS word processing, but it won't be able to keep up with the demand of newer software.
The amount of memory and storage space considered adequate rises continuously. A decade ago, a computer with 640KB of RAM and a 10MB hard disk was considered a powerful machine. Today, people who want to use the computer for serious business applications consider 8MB/200MB as a generous but not outrageous configuration.
What’s New in the pretend your PC Archives?
Screen Shot

System Requirements for Pretend your PC Archives
- First, download the Pretend your PC Archives
-
You can download its setup from given links:


